


I. Introduction▲
Une solution simple pour augmenter les performances au niveau base de données est de maîtriser la gestion des index. Vous avez sûrement lu ou déjà expérimenté l'impact de l'ajout d'un index sur les performances d'une requête.
Malheureusement, il faut bien être sensibilisé sur le nombre d'index sur une table car ils ont un coût, et en particulier pour les opérations UPDATE, DELETE et INSERT INTO.
Afin de démontrer ce coût, nous allons utiliser le « couteau suisse » de JMeter associé à Benerator.
Avant de commencer, je vous conseille de réviser vos cours sur la gestion des index (comment créer un index, comment il marche...). Attention car chaque moteur de base de données a ses particularités.
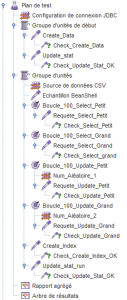
II. Plan de test▲
Afin de démontrer le coût d'un index nous allons faire cent itérations des étapes suivantes :
- Mesurer le temps de réponse d'une requête SQL de selection des données (select)
- Mesurer le temps de réponse d'une requête SQL de modification des données (update)
- Créer un index
- Mettre à jour les statistiques de la table sur laquelle on réalise nos requêtes SQL.
Ces deux types de requête SQL (select et update) nous permettront de montrer l'impact du nombre d'index sur les temps de réponse. Pour chaque type de requête, on réalisera deux requêtes SQL qui modifieront/sélectionneront des volumes de données (90% et 10%) différents afin de mesurer l'impact du volume de données.
La mise à jour des statistiques nous permettra d'être sûr que le moteur SQL d'Oracle prenne les meilleurs décision concernant nos requêtes SQL.
Implémenter cette stratégie de test avec JMeter se fera de la manière suivante.
Notre plan de test sera le suivant.
Initialisation :
- Création des données en base à l'aide de Benerator
- Mise à jour des statistiques de la table nouvellement créée
Run:
-
Boucler tant qu'il y a des index à créer
- Exécution de 10 requêtes SQL Select
- Exécution de 10 requêtes SQL Update
- Création d'index
- Mise à jour des statistiques
Au final on aura.
III. Mise en place de l'environnement▲
Les tests sont réalisés sur Oracle 11g Express Edition installé sur un Windows Vista 32bits. La version de JMeter utilisée est la 2.7.
IV. Mise en place de la partie Benerator▲
Une fois l'environnement mis en place il nous faut un jeu de données pour notre test. Jeu de données qui sera créé par Benerator.
Et comme nous l'avons vu dans un précédent article, il vaut mieux avoir un jeu de données conséquent afin de débusquer le maximum de problèmes.
Malheureusement, le serveur de test n'étant pas un monstre de puissance, nous nous limiterons à :
- une table de 1100 lignes ;
- 40 requêtes SQL par itération ;
- la création de 100 index.
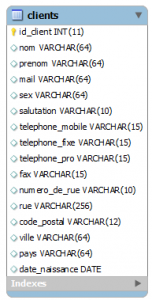
Nous allons implémenter ce schéma relationnel avec seulement une table afin de simplifier nos tests.
La première étape consiste à ajouter les librairies JDBC Oracle dans le répertoire lib de Benerator.
Maintenant, créons le fichier de configuration permettant de générer le jeu de données.
En suivant mon tutoriel sur Benerator, on aura.
CREATE SEQUENCE seq_hibernate_id_gen START WITH 1;
CREATE TABLE Clients (
id_client INT NOT NULL,
nom VARCHAR(64),
prenom VARCHAR(64),
mail VARCHAR(64),
sex VARCHAR(64),
salutation VARCHAR(10),
telephone_mobile VARCHAR(15),
telephone_fixe VARCHAR(15),
telephone_pro VARCHAR(15),
fax VARCHAR(15),
numero_de_rue VARCHAR(10),
rue VARCHAR(256),
code_postal VARCHAR(12),
ville VARCHAR(64),
pays VARCHAR(64),
date_naissance DATE,
PRIMARY KEY (id_client)
);DROP SEQUENCE seq_hibernate_id_gen;
DROP TABLE Clients;V. Mise en place du plan de test avec JMeter - Configuration du pool de connexions Oracle▲
La prochaine étape est de créer le plan de test avec JMeter.
Avant de commencer, ajoutons les librairies JDBC Oracle dans le répertoire lib de JMeter.
Afin de pouvoir exécuter les requêtes JDBC, il nous faut un élément Configuration de connexion JDBC.
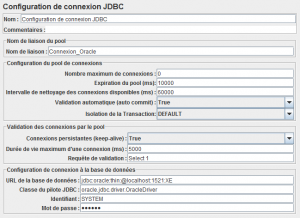
C'est ici que l'on va configurer le pool de connexions vers notre base de données Oracle.
VI. Mise en place du plan de test avec JMeter - Initialisation▲
VI-A. Création des données en base▲
L'initialisation du test est réalisée avec l'élément Groupe d'unités de début qui a été introduit dans la version 2.5 de Jmeter.
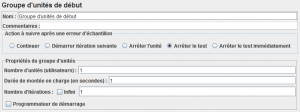
Pour l'appel de Benerator qui va nous permettre de peupler notre base de données, on utilise l'élément Appel de processus système, une nouveauté de la version 2.7 de Jmeter.
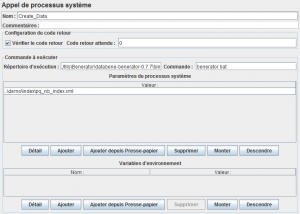
On n'oublie pas de tester la réponse avec un élément Assertion Réponse.
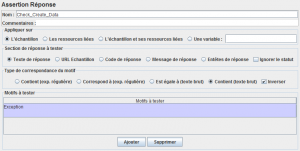
Attention cette méthode ne marche pas avec un test en cluster, car chaque injecteur essayera de remplir la base de données.
VI-B. Mise à jour des statistiques▲
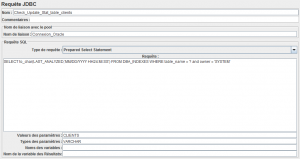
Mettons à jour les statistiques de la table fraîchement créée à l'aide de l'élément Requête JDBC
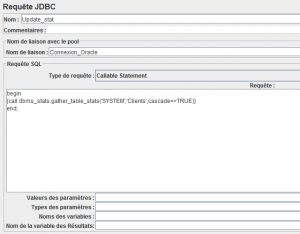
Afin de s'assurer que la mise à jour s'est bien passée, on va vérifier avec un élément Assertion Réponse qu'il n'y a pas de code d'erreur Oracle (ORA-) dans la réponse.
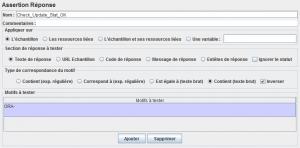
Ceux qui veulent avoir la date exacte de mise à jour des statistiques peuvent utiliser cette requête SQL.
SQL> SELECT index_name, to_char(LAST_ANALYZED,'MM/DD/YYYY HH24:MI:SS') FROM DBA_INDEXES WHERE TABLE_NAME = 'CLIENTS' AND owner = 'SYSTEM';
INDEX_NAME TO_CHAR(LAST_ANALYZ
------------------------------ -------------------
SYS_C007059 07/17/2012 21:49:01Bien sûr il est possible de les intégrer à JMeter avec l'élément Requête JDBC.
VII. Mise en place du plan de test avec JMeter - Run▲
La phase d'initialisation du test est prête, regardons d'un peu plus près le test.
VII-A. Boucler tant qu'il y a des index à créer▲
Ajoutons un Groupe d'unités .
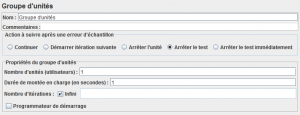
L'arrêt du test étant paramétré par le nombre d'index à créer, on choisit " infini " comme nombre d'itérations.
Nous allons utiliser un fichier CSV contenant la liste des commandes de création des index. Ce fichier sera utilisé par l'élément Source de données CSV.
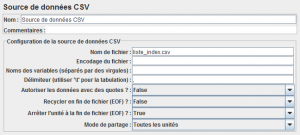
On laisse le paramètre « Arrêter l'unité à la fin de fichier (EOF)? » à true afin que le test s'arrête lorsqu'il n'y a plus d'index à créer.
VII-B. Exécution de 10 requêtes SQL Select & Exécution de 10 requêtes SQL Update▲
Maintenant, on ajoute une boucle (élément Contrôleur Boucle ) de dix itérations pour chaque requête SQL dont on veut mesurer l'impact des index sur le temps de réponse.Les dix itérations nous permettent :
- d'avoir des résultats plus précis (moyenne, médian, percentile...) ;
- que les données requêtées soient en mémoire et non sur disque afin de comparer toujours la même chose (on élimine les accès disque de nos mesures).
Pour chaque type de requête, on aura deux requêtes (grand et petit) avec un critère de sélection (clause where) différent.
Cela nous permet de voir l'impact du nombre de modifications à faire sur l'index sur les temps de réponse mesurés.
Les requêtes de type "grand" correspondent à un select ou un update de quatre-vingt-dix pour cent de notre table (mille lignes sur les mille cent lignes).
"Petit" correspond aux dix pour cent restants.
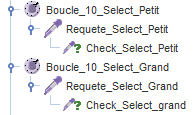
- Requête SQL : Select
Dans des éléments Requête JDBC, on ajoute la requête suivante.
SELECT id_client,nom,prenom,mail,sex,salutation,telephone_mobile,telephone_fixe,telephone_pro,fax,numero_de_rue,rue,code_postal,ville,pays,date_naissance FROM clients WHERE pays = 'Germany'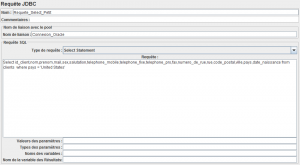
Ne pas oublier de tester la réponse de notre requête.
Requête SQL : Update
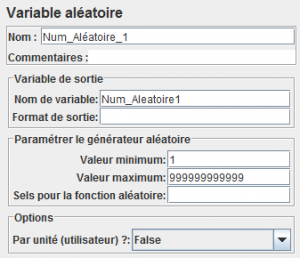
Pour être sûr que ce soit un update différent à chaque itération, on ajoute un élément Compteur qui va nous créer un numéro unique.
Ce numéro sera utilisé pour les numéros de téléphone et de fax.
Ajoutons l'élément Requête JDBC.
La requête utilisée sera.
UPDATE clients SET telephone_mobile = ?, telephone_fixe = ?, telephone_pro = ?, fax = ? WHERE pays = 'Germany'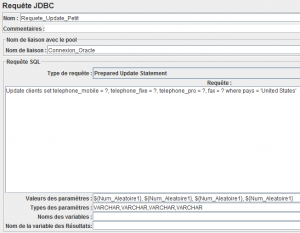
Avec l'ajout du contrôle de la réponse SQL, on aura.
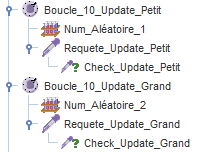
VII-C. Création d'index▲
Encore une fois, nous utiliserons l'élément Requête JDBC.La requête SQL de création des index sera directement récupérée du fichier CSV défini précédemment.
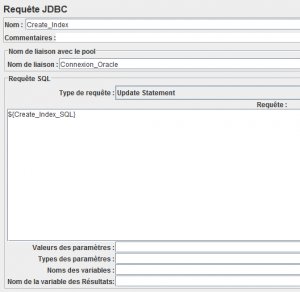
VII-D. Mise à jour des statistiques▲
Il suffit de faire une copie de celui de la phase d'initialisation.
VII-E. Récupération des résultats▲
Nous allons récupérer les résultats de notre test dans un fichier CSV à l'aide de l'élément Rapport agrégé .
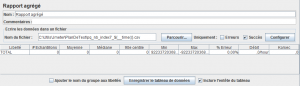
Dans le fichier CSV, il nous manque les informations comme le nombre d'index et la requête SQL de création de l'index.
Pour obtenir le nombre d'index, l'élément Echantillon BeanShell associé à la fonction __counter sera utilisé.
Pour la requête SQL de création de l'index, elle est déjà dans la variable ${Create_Index_SQL} .
Afin que ces informations soient écrites dans notre fichier CSV, il faut utiliser la propriété sample_variables du fichier properties de JMeter de la manière suivante.
# Optional list of JMeter variable names whose values are to be saved in the result data files.
# Use commas to separate the names. For example:
sample_variables=iteration_number,Create_Index_SQLLe fichier CSV sera de la forme suivante.
timeStamp,elapsed,label,responseCode,responseMessage,threadName,dataType,success,bytes,grpThreads,allThreads,Latency,"iteration_number","Create_Index_SQL"
2012/07/29 11:52:22.150,6686,Create_Data,,,Groupe d'unités de début 1-1,text,true,2399,1,1,0,null,null
2012/07/29 11:52:28.729,144,Update_stat,200,OK,Groupe d'unités de début 1-1,text,true,42,1,1,32,null,null
2012/07/29 11:52:28.972,0,Echantillon BeanShell,200,OK,Groupe d'unités 1-1,text,true,1,1,1,0,1,create index ix_clients_0001 on clients(pays)
2012/07/29 11:52:28.972,16,Requete_Select_Petit,200,OK,Groupe d'unités 1-1,text,true,17898,1,1,13,1,create index ix_clients_0001 on clients(pays)
2012/07/29 11:52:28.989,2,Requete_Select_Petit,200,OK,Groupe d'unités 1-1,text,true,17898,1,1,0,1,create index ix_clients_0001 on clients(pays)
2012/07/29 11:52:28.992,2,Requete_Select_Petit,200,OK,Groupe d'unités 1-1,text,true,17898,1,1,0,1,create index ix_clients_0001 on clients(pays)
2012/07/29 11:52:28.994,2,Requete_Select_Petit,200,OK,Groupe d'unités 1-1,text,true,17898,1,1,0,1,create index ix_clients_0001 on clients(pays)
2012/07/29 11:52:28.997,2,Requete_Select_Petit,200,OK,Groupe d'unités 1-1,text,true,17898,1,1,0,1,create index ix_clients_0001 on clients(pays)
2012/07/29 11:52:28.999,2,Requete_Select_Petit,200,OK,Groupe d'unités 1-1,text,true,17898,1,1,0,1,create index ix_clients_0001 on clients(pays)
2012/07/29 11:52:29.002,2,Requete_Select_Petit,200,OK,Groupe d'unités 1-1,text,true,17898,1,1,0,1,create index ix_clients_0001 on clients(pays)
2012/07/29 11:52:29.004,2,Requete_Select_Petit,200,OK,Groupe d'unités 1-1,text,true,17898,1,1,0,1,create index ix_clients_0001 on clients(pays)
2012/07/29 11:52:29.007,2,Requete_Select_Petit,200,OK,Groupe d'unités 1-1,text,true,17898,1,1,0,1,create index ix_clients_0001 on clients(pays)
2012/07/29 11:52:29.009,2,Requete_Select_Petit,200,OK,Groupe d'unités 1-1,text,true,17898,1,1,0,1,create index ix_clients_0001 on clients(pays)
2012/07/29 11:52:29.012,15,Requete_Select_Grand,200,OK,Groupe d'unités 1-1,text,true,184357,1,1,0,1,create index ix_clients_0001 on clients(pays)
2012/07/29 11:52:29.028,16,Requete_Select_Grand,200,OK,Groupe d'unités 1-1,text,true,184357,1,1,0,1,create index ix_clients_0001 on clients(pays)
2012/07/29 11:52:29.045,16,Requete_Select_Grand,200,OK,Groupe d'unités 1-1,text,true,184357,1,1,0,1,create index ix_clients_0001 on clients(pays)
2012/07/29 11:52:29.063,16,Requete_Select_Grand,200,OK,Groupe d'unités 1-1,text,true,184357,1,1,0,1,create index ix_clients_0001 on clients(pays)
2012/07/29 11:52:29.080,15,Requete_Select_Grand,200,OK,Groupe d'unités 1-1,text,true,184357,1,1,0,1,create index ix_clients_0001 on clients(pays)VIII. Analyse des résultats du test▲
Il ne reste plus qu'à charger notre fichier CSV avec l'outil de notre choix.
Attention les résultats obtenus ne seront pas forcement ceux que vous obtiendrez lors de vos tests, car un certain nombre de paramètres (taille de la mémoire, taille des caches...) peuvent modifier le comportement de notre test.
Comme on peut le voir, de manière globale, plus il y a d'index et plus le temps de réponse des requêtes SQL sera grand.
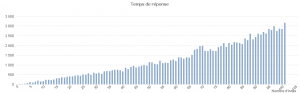
Regardons d'un peu plus près les temps de réponse par type de requête.
VIII-A. Requêtes Select▲
On remarque le nombre d'index n'a pas d'influence sur les temps de réponse. Ce qui est normal, car l'index le plus pertinent est créé dès la première itération et c'est celui-là qui sera utilisé tout au long de notre test par le moteur d'Oracle pour exécuter nos requêtes Select.
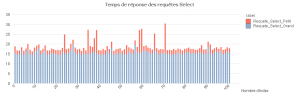
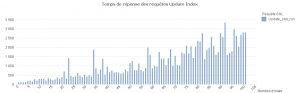
VIII-B. Requêtes Update▲
Comme on peut le voir sur notre graphique, les temps de réponse de nos requêtes Update sur mille lignes (sur les mille cent lignes de notre table) augmentent avec le nombre d'index.
Ce qui peut s'expliquer par le fait que chaque index doit aussi être mis à jour lors de l'update de la table.

Les résultats pour les requêtes « petit » sont plus mitigés . On remarque que dans l'absolue il vaut mieux avoir un nombre restreint d'index sur notre table pour ne pas dégrader les temps de réponse. Mais l'augmentation de ces temps de réponse n'est pas régulière.
Ce qui assoit encore une fois la devise « Ne devinez pas, mesurez » que j'ai abordé à la Breizhcamp 2012 . Il faut toujours faire attention aux conseils sur les bonnes pratiques de performance, qui dépendent essentiellement du contexte technique.

Une analyse plus approfondie nous permettrait de connaître la cause de ce comportement (activité i/o différente entre chaque itération, gestion des caches différentes...).
VIII-C. Requêtes Create Index▲
Avec ce graphique, on peut conclure que le temps de réponse de la création d'un index dépend de sa complexité.
Par exemple, la création d'un index composite avec beaucoup d'éléments (itération 61) ou d'un index utilisant une fonction (à partir de l'itération 70) prend plus de temps que la création d'un index simple (index créés lors des premières itérations).
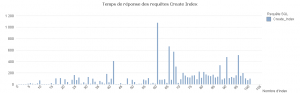
VIII-D. Requêtes Update Statistiques▲
De même que pour les requêtes update, la durée de la mise à jour des statistiques augmente avec le nombre des index.
IX. Conclusion▲
Comme on a pu le voir, la gestion des index SQL n'est pas aussi simple, car l'ajout d'index n'augmente pas toujours les performances alors que leur maintenance a un coût.
Mes conseils sont :
- d'apprendre le fonctionnement d'un index;
- d'appliquer la devise « Ne devinez pas, mesurez ».
Ces deux conseils vous permettront de bien choisir vos index, ainsi que leur nombre.
Nombre qui pourra être élevé et engendra un impact positif sur les performances comme j'ai pu le voir lors de certaines de mes missions.
Mais avant d'augmenter le nombre d'index, il faut bien penser à faire des tests afin de mesurer si le coût de la maintenance des index est inférieur aux gains obtenus.
Dernier conseil, l'aide d'un administrateur de bases de données peut s'avérer utiles, voir indispensables dans certain cas.