


I. Applications autonomes▲
CouchDB peut être utile pour plusieurs parties d'un logiciel. Puisque MapReduce et le mécanisme de réplication fonctionnent de manière incrémentale, ils sont particulièrement adaptés aux documents interactifs et aux tâches de traitement des données. Cela correspond à la charge de travail que subissent bon nombre d'applications web. En ajoutant à cela l'interface HTTP de CouchDB, cela en fait une solution naturellement adaptée à ce milieu.
Dans cette partie, nous verrons une application web orientée document : un blogue basique. Comme plus petit dénominateur commun, nous utiliserons du bon vieux HTML et du JavaScript. Les enseignements que vous pourrez en tirer s'appliqueront à Django, Rails, aux intergiciels basés sur Java et même aux tâches intensives de fouille de données avec MapReduce. Que vous exploitiez une petite installation ou un cluster industriel, l'API de CouchDB est la même.
Il n'y a pas de réponse magique quant au framework de développement que vous devriez utiliser avec CouchDB. Nous avons vu fonctionner des applications avec presque tous les langages répandus et avec n'importe quel framework. Pour notre exemple, nous utilisons une architecture deux tiers : CouchDB comme tiers de persistance des données et le navigateur comme interface d'accès à celles-ci. Nous pensons qu'il s'agit d'un modèle viable pour de nombreux logiciels orientés documents. De plus, c'est un bon moyen d'enseigner CouchDB, car nous pouvons estimer sans grand risque que vous disposez d'un navigateur sous la main sans avoir à poser un quelconque prérequis sur votre maîtrise des langages côté serveur.
I-A. Utiliser la bonne version▲
Cette partie est interactive, alors soyez prêt à la suivre avec votre ordinateur portable et à faire fonctionner une base de données CouchDB. Nous avons complètement créé cette application et avons publié l'intégralité du code source. C'est pourquoi vous commencerez par télécharger la dernière version de l'application et que vous l'installerez sur votre instance de CouchDB.
Un des défis posés par ce livre pour son écriture et son édition est que CouchDB évolue très vite. Les fondamentaux n'ont pas changé depuis longtemps et ne changeront probablement pas avant longtemps, mais ce qui les entoure évolue rapidement pour atteindre la version 1.0 de CouchDB.
Ce livre sera édité à l'époque de la version 0.10.0. La majeure partie du code a été rédigée avec la version 0.9.1 et le tronc courant du développement qui va devenir la 0.10.0. Dans cette partie, nous travaillerons avec deux autres logiciels : CouchApp, un ensemble d'outils pour éditer et partager du code d'application CouchDB, et Sofa, le blogue d'exemple.
Visitez http://couchapp.org pour obtenir les dernières informations concernant CouchApp.
En tant que lecteur, il est de votre responsabilité d'utiliser les bonnes versions de ces logiciels. Pour CouchApp, la bonne version est toujours la dernière. La bonne version de Sofa dépend de la version de CouchDB que vous utilisez. Pour savoir quelle version vous utilisez, faites :
curl http://127.0.0.1:5984Vous devriez voir l'une de ces trois réponses :
{"couchdb":"Welcome","version":"0.9.1"}
{"couchdb":"Welcome","version":"0.10.0"}
{"couchdb":"Welcome","version":"0.11.0a858744"}Ces trois lignes correspondent aux versions 0.9.1, 0.10.0 et au tronc de développement. Si vous utilisez CouchDB 0.9.1 ou plus récent, vous devriez mettre à jour pour atteindre au moins la version 0.10.0, puisque Sofa utilise des fonctionnalités qui ne sont pas présentes avant. Il existe toutefois une ancienne version de Sofa qui fonctionnera, mais ce livre décrit des fonctionnalités et des APIs qui sont liés à la version 0.10.0 de CouchDB. Il est probable qu'au jour où vous lirez ceci, il existera une version 0.9.2 ou 0.10.1, voire une 0.10.2. Utilisez la dernière mise à jour de la version que vous préférez.
Le tronc fait référence à la dernière version de développement de CouchDB disponible sur le dépôt Subversion d'Apache. Nous vous recommandons d'utiliser une version publiée de CouchDB, mais en tant que développeurs, nous utilisons souvent le tronc de développement. La branche maîtresse de Sofa aura tendance à fonctionner avec le tronc, donc si vous désirez rester à la pointe, vous savez comment vous y prendre.
I-B. JavaScript portable▲
Si le JavaScript ne vous est pas familier, nous espérons que les exemples qui vous sont donnés s'accompagnent de suffisamment d'éléments de contexte et d'explications pour que vous puissiez suivre. Si le JavaScript vous est familier, vous serez sans doute heureux de savoir que CouchDB intègre les fonctions de vue et de patrons de rendu (ou modèles de documents).
L'un des avantages à bâtir des applications qui nécessitent uniquement CouchDB est qu'elles peuvent être répliquées par le mécanisme de la base. Cela signifie que votre application, si vous la faites uniquement reposer sur CouchDB, pourra être utilisée hors ligne sans développement complémentaire. Avoir des données locales change considérablement la donne pour les utilisateurs, mais nous ne rentrerons pas ici dans les détails. Les applications qui nécessitent uniquement CouchDB pour fonctionner sont appelées « CouchApps ».
Les CouchApps sont un excellent moyen pour enseigner CouchDB parce qu'elles ne requièrent pas de choisir un langage ou un framework ; nous travaillerons directement avec CouchDB, ce qui permet aux lecteurs de comprendre rapidement la structure de l'application. Une fois que vous aurez réalisé l'application d'exemple, vous en aurez suffisamment vu pour savoir appliquer CouchDB à votre problématique. Si vous ne connaissez pas trop Ajax, vous l'apprendrez un peu, tout comme vous en apprendrez un peu sur jQuery, et nous espérons que vous trouverez l'expérience relaxante.
I-C. Les applications sont des documents▲
Les applications sont stockées comme des design documents (cf. Figure 1, CouchDB exécute une application stockée dans un design document). Vous pouvez répliquer les design document comme n'importe quoi d'autre dans CouchDB. Puisque les design document peuvent être répliqués, l'application entière peut l'être aussi. Les CouchApps peuvent être mises à jour par réplication, mais les utilisateurs peuvent aussi les bifurquer [NdT : fork en anglais] et modifier le code source comme bon leur semble.
« Quand je pense à la réplication d'applications conçues pour fonctionner sur un nœud, je me souviens de mes années de collège, quand nous partagions entre amis des programmes sur les TI-85 que nous étions obligés d'avoir », déclare J. Chris. « Deux calculatrices pouvaient être connectées par un câble et nous pouvions transférer des fafiots de sciences physiques. Hangman, quelques aventures multi-joueurs en mode texte, et, au paroxysme de nos talents, je crois me souvenir qu'un clone de Doom tournait aussi. »
« Les programmes de la TI-85 étaient écrits en Basic, donc tout le monde passait son temps à bidouiller les bidouillages des autres. Peut-être même que le programme le plus ridicule qui fût était une version de Spy Hunter que vous contrôliez avec votre esprit. L'idée était que vous pouviez influencer le générateur de nombres pseudoaléatoires en vous concentrant suffisamment et, par là même, contrôler le jeu. Ça ne marchait d'ailleurs pas du tout. Quoiqu'il en fût, l'important est que quand vous donnez accès aux autres à votre code source, personne ne peut prédire ce qui va se passer. »
Si certains n'apprécient pas le design de votre application, ils peuvent modifier les CSS. Si d'autres n'approuvent pas vos choix d'interfaces, ils peuvent améliorer le HTML. S'ils veulent modifier une fonctionnalité, ils peuvent éditer le code JavaScript. En poussant la logique à l'extrême, ils pourraient bifurquer complètement votre application pour répondre à leur propre besoin. Quand ils montreront leur version à leurs amis et collègues, donc avec un peu de chance, à vous aussi, il est possible que d'autres personnes veuillent apporter des améliorations.
En tant que concepteur originel, vous contrôlez ce que devient votre version et pouvez accepter ou refuser les modifications comme bon vous semble. Si quelqu'un se mélange les pinceaux et détruit son application locale, il peut récupérer à nouveau la vôtre, comme le montre la Figure 2, Répliquer les modifications apportées à une application avec un groupe d'amis.
Bien sûr, ce n'est peut-être pas votre tasse de thé. Ne vous inquiétez pas, vous pouvez être aussi restrictif que vous le désirez avec CouchDB. Vous pouvez limiter l'accès aux données comme vous le voulez, mais soyez conscient des occasions sur lesquelles vous passez peut-être. Il existe des compromis entre la collaboration ouverte à tous les vents et la restriction absolue des accès.
Une fois que vous avez achevé la procédure d'installation, vous serez capable de voir tout le code de l'application Sofa, aussi bien dans votre éditeur de texte que sous la forme d'un design document dans Futon.
I-D. Autosuffisance▲
Que se passe-t-il si vous joignez un fichier HTML à un document ? La même chose. CouchDB peut servir directement des pages web. Bien sûr, vous aurez peut-être aussi besoin d'images, de feuilles de style ou de scripts. Aucun souci : ajoutez ces fichiers comme des pièces jointes et liez-les entre eux avec des URIs relatives.
Prenons du recul. Qu'avons-nous à présent ? Un moyen de servir des documents HTML et d'autres fichiers statiques sur le Web. Vous pouvez donc créer un publier des sites web traditionnels avec CouchDB. Fantastique ! Mais n'est-ce pas réinventer la roue ? Eh bien, le changement, c'est que nous avons aussi une base de données derrière. Nous pouvons attaquer cette base de données avec le JavaScript envoyé dans nos pages web. Bienvenu à bord de la Rolls-Royce !
Les fonctionnalités de CouchDB permettent de bâtir des applications web autonomes s'appuyant sur une base de données puissante. Pour preuve, regardez l'interface d'administration Futon : elle est intégrée à CouchDB. Futon est une application de gestion de base de données pleinement opérationnelle avec de HTML, du CSS et du JavaScript. Et rien d'autre. CouchDB est fait pour s'entendre avec les applications web.
I-E. Dans la nature▲
Il existe de nombreux exemples de CouchApps dans la nature. Cette section contient des captures d'écran de quelques sites et applications qui utilisent une architecture CouchDB autonome.
Damien Katz, inventeur de CouchDB et auteur de la préface de ce livre, a cherché à voir combien de temps serait nécessaire à implémenter un calendrier partagé avec des mises à jour en temps réel quand un évènement est modifié sur le serveur. Cela lui a pris l'après-midi, grâce soit rendue à quelques greffons impressionnants du framework JQuery. Le calendrier fonctionne toujours sur le serveur de J. Chris. Reportez-vous à la Figure 3, Calendrier de groupe.
Jason Davies s'est appuyé sur CouchDB pour le stockage du site Ely Service. Les détails techniques sont donnés sur son blogue. Reportez-vous à la Figure 4, Ely Service.
Jason a aussi converti le site commercial de sa mère, Bet Ha Bracha, en une CouchApp. Il utilise le gestionnaire _update pour s'adresse aux passerelles de transaction. Reportez-vous à la Figure 5, Bet Ha Bracha.
Processing JS est une bibliothèque qui permet d'écrire des animations qui s'exécutent dans le navigateur. Processing JS Studio est une galerie recensant les « croquis » de Processing JS. Reportez-vous à la Figure 6, Processing JS Studio.

Swinger est une CouchApp pour créer et partager des diaporamas. Il repose sur Sammy JavaScript application framework. Reportez-vous à la Figure 7, Swinger.
Nymphormation est un site de partage d'adresses et de classification conçu par Benoît Chesneau. Il utilise l'authentification par cookie de CouchDB et permet le partage des adresses par les mécanismes de réplication. Reportez-vous à la Figure 8, Nymphormation.
Boom Amazing est une CouchApp développée par Alexander Lang qui vous permet de pivoter, de zoomer et de faire des panoramiques de fichiers SVG, le tout en mémorisant les différentes positions pour pouvoir les rejouer lors d'une présentation (dixit le Boom Amazing README). Reportez-vous à la Figure 9, Boom Amazing.
Le client Twitter CouchDB fut une des premières CouchApp créées. Il est décrit par l'article du blogue de J. Chris My Couch or Yours, Shareable Apps are the Future. La capture d'écran présentée par la Figure 10, Client Twitter montre un nuage de mots généré par une vue MapReduce des gazouillis archivés dans la base CouchDB. Ce nuage est stabilisé à partir de la vue globale, ce qui garantit que les mots communs ne domineront pas le nuage.
Toast est un système de communication instantané qui permet aux utilisateurs de créer des salons et d'y inviter d'autres personnes. À l'origine, c'était une démonstration de la boucle d'évènements _changes, mais il a fini par être un moyen de communication. Reportez-vous à la figure Figure 11, Toast.
Sofa est l'application d'exemple de cette partie, et elle a été déployée par différents auteurs sur le Web. La capture d'écran illustrée par la Figure 12, Sofa a été prise sur le Tumblelog de Jan. Pour en voir davantage, vous pouvez visiter le site web de J. Chris qui est en ligne depuis fin 2008.

I-F. Résumé▲
J. Chris a décidé de migrer son blogue de Ruby on Rails vers CouchDB. Il a commencé par exporter les objets ActiveRecords de Rails vers leur équivalent JSON en abandonnant quelques fonctionnalités pour en intégrer d'autres dans les codes HTML et JavaScript.
Le moteur de blogue qui en résulte offre les fonctionnalités de contrôle d'accès, de commentaires libres avec la possibilité de les modérer, de flux Atom, de formatage Markdown, etc. Le sujet principal de ce livre n'est pas jQuery, donc même si nous utilisons cette bibliothèque JavaScript, nous nous retiendrons de creuser ce sujet. Les lecteurs familiers des requêtes XML HTTP asynchrones (asynchronous XMLHttpRequests, XHR) devraient se sentir chez eux en présence du code. Gardez toutefois à l'esprit que les extraits de code et les illustrations de cette partie passent sous silence certains détails.
Nous allons étudier cette application et voir comment elle met en pratique les fonctionnalités de base de CouchDB. Les compétences acquises dans cette partie devraient pouvoir s'appliquer dans tous les domaines où CouchDB a sa place, que vous comptiez bâtir une CouchApp que vous hébergez vous-mêmes ou non.
II. Travailler avec l'application d'exemple▲
Si vous désirez installer et bidouiller votre propre version de Sofa pendant que vous lisez les chapitres suivants, sachez que nous utiliserons CouchApp pour télécharger le code source au fur et à mesure de notre exploration.
Nous sommes vraiment enjoués par la perspective de déployer des applications dans CouchDB, car, comme tout est dans un seul conteneur, cela encourage les utilisateurs à contrôler non plus uniquement les données, mais aussi le code source, ce qui permettra à un plus grand nombre de personnes de bâtir des applications web personnelles. Et quand l'heure de gloire vient pour l'application que vous bidouilliez dans votre temps libre, la capacité de CouchDB à passer à l'échelle ne fait pas de mal !
Dans CouchDB, un design document contient un mélange de langages de développement (HTML, JS, CSS) qui sont soit des pièces jointes, soit des attributs du design document. Idéalement, c'est votre environnement de développement qui se charge de tous ces détails. Plus encore, vous êtes habitué à la coloration syntaxique, à la vérification des instructions, à la documentation intégrée, aux macros, aux assistants, etc. À côté, l'édition de code JavaScript intégré dans une chaîne JSON ne fait pas très contemporaine.
Fort heureusement, nous nous sommes evertués à fournir une solution. Entrez dans l'univers de CouchApp. CouchApp vous permet de concevoir des applications CouchDB selon une approche de répertoires hiérarchisés : les éléments sont séparés, les fichiers .js sont clairement ordonnés, vos éléments statiques (CSS, images) ont leur place désignée, et la simplicité de la commande couchapp push vous évite d'avoir à sauvegarder votre application en tant que design document dans CouchDB. Besoin de modifier quelque chose ? Utilisez couchapp push et vous voilà parti !
Ce chapitre vous guide à travers les étapes d'installation de CouchApp. Vous y découvrirez quels autres assistants s'y trouvent pour faciliter votre vie. Une fois que nous aurons CouchApp, nous l'utiliserons pour installer et déployer Sofa sur une base de données CouchDB.
II-A. Installer CouchApp▲
Le script Python de CouchApp tout comme le framework JavaScript que nous utiliserons a été réalisé lors de la conception de cette application d'exemple. Ils sont désormais utilisés par plusieurs applications et disposent d'une liste de diffusion, d'un wiki et d'une communauté de hackers. Il vous suffit de chercher « couchapp » sur l'Internet pour trouver les dernières informations à ce sujet. Nous remercions particulièrement Benoît Chesneau d'avoir conçu et de maintenir cette bibliothèque (et aussi pour contribuer au code Erlang de CouchDB ainsi qu'à des bibliothèques Python).
CouchApp est plus facile à installer en utilisant le script Python easy_install intégré au paquet setuptools. Si vous êtes sur Mac, easy_install devrait être disponible. Si vous êtes sur Debian (ou un dérivé comme Ubuntu) et que le paquet n'est pas installé, vous pouvez l'installer ainsi :
sudo apt-get install python-setuptoolsUne fois que vous avez easy_install, installer CouchApp se fait ainsi :
sudo easy_install -U couchappAvec de la chance, cela fonctionne et vous êtes prêt à utiliser CouchApp. Si ce n'est pas le cas, lisez plus avant…
Le problème le plus couramment rencontré lors de l'installation de CouchApp est lié à d'anciennes versions des dépendances, tout particulièrement la version d'easy_install. Si vous obtenez une erreur lors de l'installation, la meilleure chose à faire est de tenter une mise à jour du paquet setuptools puis de réessayer, ce qui se fait ainsi :
sudo easy_install -U setuptools
sudo easy_install -U couchappSi vous rencontrez d'autres problèmes, consultez le guide de dépannage de setuptools pour Python, ou consultez la liste de diffusion CouchApp.
II-B. Utiliser CouchApp▲
Installer CouchApp avec easy_install devrait, comme on dit, être un jeu d'enfant. Si cela se déroule sans accroc, il devrait se charger de résoudre les dépendances et ajouter l'utilitaire couchapp dans le PATH du système pour que vous puissiez tout de suite exécuter :
couchapp --helpNous utiliserons les commandes clone et push. clone récupère une application à partir d'une instance disponible sur le réseau et l'enregistre sur votre disque. Quant à push, il déploie une application CouchDB autonome depuis votre disque vers un serveur sur lequel vous avez des privilèges d'administration.
Nous utiliserons les commandes clone et push. clone récupère une application à partir d'une instance disponible sur le réseau et l'enregistre sur votre disque. Quant à push, il déploie une application CouchDB autonome depuis votre disque vers un serveur sur lequel vous avez des privilèges d'administration.
II-C. Télécharger le code source de Sofa▲
Il existe trois moyens de se procurer le code source de Sofa. Les trois sont similaires, c'est surtout une question de convenance personnelle et de ce que vous prévoyez de faire avec. Le moyen le plus simple est d'utiliser CouchApp pour cloner Sofa depuis une instance existante. Si vous n'avez pas installé CouchApp, vous pouvez lire le code source (mais pas l'installer et l'exécuter) en téléchargeant l'archive ZIP ou TAR. Si vous êtes du genre à bidouiller Sofa et vouliez rejoindre la communauté des développeurs, vous devriez exploiter le dépôt Git. Nous décrirons ces trois méthodes tour à tour. Avant cela, profitez de la Figure 13. un oiseau heureux pour faciliter toute installation frustrante.

II-C-1. Cloner avec CouchApp▲
L'un des moyens les plus faciles d'obtenir le code source de Sofa est de le cloner directement depuis le blogue de J. Chris en utilisant la commande clone de CouchApp. Cela téléchargera les design documents et les stockera sur votre disque. La commande clone exploite une URL d'un design document qui peut être stocké dans n'importe quelle instance de CouchDB accessible par HTTP. Pour cloner la version de Sofa depuis le blogue de J. Chris, utilisez la commande suivante :
couchapp clone http://jchrisa.net/drl/_design/sofaVous devriez voir :
[INFO] Cloning sofa to ./sofaMaintenant que vous avez Sofa sur votre disque, vous pouvez passer à la section Déployer Sofa pour effectuer quelques modifications avant de le mettre en place sur votre CouchDB.
II-C-2. Archives ZIP et TAR▲
Si vous comptez simplement lire attentivement le code source durant votre lecture, celui-ci est disponible sous la forme classique d'archives ZIP et TAR. Pour obtenir la version ZIP, utilisez votre navigateur pour vous rendre sur :http://github.com/couchapp/couchapp/zipball/master. Si vous préférez le format TAR, allez sur : http://github.com/couchapp/couchapp/tarball/master.
II-C-3. Rejoindre la communauté de développeurs de Sofa sur GitHub▲
La version la plus à jour de Sofa sera toujours disponible sur son dépôt public. Si vous désirez utiliser les derniers développements et fournir des correctifs au dépôt, le meilleur moyen de le faire est avec Git et GitHub.
Git est un système de distribué de contrôle de version qui permet à des groupes de développeurs de conserver la trace des modifications apportées à un logiciel et de les échanger. Si vous connaissez Git, vous n'aurez aucun problème à l'utiliser pour travailler avec Sofa. En revanche, si vous n'avez jamais utilisé Git par le passé, sachez que l'apprentissage est un peu long, donc, selon votre tolérance vis-à-vis des nouveaux logiciels, vous préférerez peut-être garder ça pour un autre jour - ou tout simplement plonger dedans la tête la première ! Pour trouver plus d'informations sur Git et comment l'installer, référez-vous à la page d'accueil officielle de Git. Pour des trucs et astuces ou de l'aide, référez-vous aux guides GitHub.
Pour obtenir Sofa (et tout l'historique de développement) avec Git, utilisez la commande suivante :
git clone git://github.com/jchris/sofa.gitMaintenant que vous avez obtenu les sources, regardons-les !
II-C-4. L'arbre du code source de Sofa▲
Une fois que vous avez obtenu le code source par l'une des méthodes précitées, vous avez de quoi travailler sur votre disque. Le texte ci-dessous est obtenu par la commande tree sur le répertoire de Sofa pour lister son contenu. Certaines sections sont annotées pour faire ressortir ce qui a trait aux design documents.
sofa/
|-- README.md
|-- THANKS.txtL'arbre contient des fichiers qui ne sont pas nécessaires à l'application, telle que les fichiers README et THANKS.
|-- _attachments
| |-- LICENSE.txt
| |-- account.html
| |-- blog.js
| |-- jquery.scrollTo.js
| |-- md5.js
| |-- screen.css
| |-- showdown-licenese.txt
| |-- showdown.js
| |-- tests.js
| `-- textile.jsLe répertoire _attachments abrite les pièces jointes binaires au design document. CouchDB fournit ces pièces jointes directement (plutôt que de les intégrer dans une enveloppe JSON), c'est dont là que l'on stocke les fichiers JavaScript, CSS et HTML auxquels le navigateur accèdera directement.
C'est en réalisant votre première édition du code source que vous comprendrez combien il est facile de modifier l'application.
|-- blog.jsonLe fichier blog.json contient le JSON nécessaire à la configuration d'une installation de Sofa. Pour le moment, il définit une seule valeur : le titre du blogue. Vous devriez ouvrir immédiatement ce fichier et personnaliser le champ titre - vous ne voulez probablement pas appeler votre blogue « Daytime Running Lights », donc remplacez-le par quelque chose d'amusant !
Vous pourriez ajouter d'autres paramètres du blogue dans ce fichier, comme le nombre d'éléments à afficher par page et une URL pour une page « à propos de l'auteur ». Effectuer ces changements sera facile quand vous aurez lu les chapitres suivants.
|-- couchapp.jsonNous verrons par la suite que couchapp affiche un lien vers la page d'accueil de Sofa quand la commande couchapp push est exécutée. Cela fonctionne très simplement : CouchApp recherche le champ JSON du design document à l'adresse design_doc.couchapp.index. S'il le trouve, il ajoute son contenu à l'URL du design document pour construire l'URL du blogue. Il n'y a pas d'index CouchApp de spécifié, mais le design document a une pièce jointe appelée index.html, ce qui en fait la page d'accueil. Dans le cas de Sofa, nous utilisons la valeur d'index pour orienter vers une liste des articles récents.
|-- helpers
| `-- md5.jsLe répertoire helpers résulte d'un choix arbitraire. CouchApp y mettra tous les fichiers et répertoires du design document. Dans notre cas, le code source de md5.js est encodé en JSON et stocke l'élément design_document.helpers.md5.
|-- lists
| `-- index.jsLe répertoire lists abrite une fonction JavaScript qui sera exécutée pour générer les enregistrements selon des index HTML et Atom. Vous pourriez y ajouter de nouvelles fonctions en créant de nouveaux fichiers. Les listes sont détaillées dans le Chapitre 14, lister les articles d'un blogue.
|-- shows
| |-- edit.js
| `-- post.jsLe répertoire shows abrite les fonctions que CouchDB utilise pour générer les vues HTML des articles du blogue. Il y a deux vues : l'une pour lire les articles et l'autre pour les éditer. Nous reviendrons sur ces fonctions dans les prochains chapitres.
|-- templates
| |-- edit.html
| |-- index
| | |-- head.html
| | |-- row.html
| | `-- tail.html
| `-- post.htmlLe répertoire templates se différencie des répertoires lists, shows et views, car son contenu n'est pas directement exécuté par CouchDB du côté serveur. En fait, les patrons sont injectés dans le corps des fonctions lists et shows par CouchApp lorsque l'application est envoyée au serveur. Ces macros sont détaillées dans le Chapitre 12, Stockage des documents. Ce qu'il faut retenir est que ce répertoire pourrait s'appeler d'une tout autre manière : il n'a pas de fonction prédéterminée au sein d'un design document ; c'est simplement un endroit choisi pour regrouper et modifier vos patrons.
|-- validate_doc_update.jsCe fichier contient la fonction JavaScript de validation utilisée par Sofa pour garantir que seul le propriétaire du blogue peut y créer des articles et que les commentaires sont en bonne et due forme. Cette fonction est détaillée dans le Chapitre 12, Stockage des documents.
|-- vendor
| `-- couchapp
| |-- README.md
| |-- _attachments
| | `-- jquery.couchapp.js
| |-- couchapp.js
| |-- date.js
| |-- path.js
| `-- template.jsLe répertoire vendor abrite du code qui est géré indépendamment de l'application elle-même. Dans le cas de Sofa, le seul paquet externe utilisé est couchapp, lequel contient le code JavaScript qui détermine la manière dont le lien est fait entre les URL de list et de show, ou encore la manière dont sont exploités les patrons.
Pendant l'opération couchapp push, les fichiers se trouvant dans le chemin vendor/**/_attachments/* sont envoyés au serveur en tant que pièces jointes du design document. Dans notre cas, le fichier jquery.couchapp.js deviendra une pièce jointe nommée couchapp/jquery.couchapp.js. Ainsi, les paquets externes peuvent inclure des fichiers qui ont le même nom.
`-- views
|-- comments
| |-- map.js
| `-- reduce.js
|-- recent-posts
| `-- map.js
`-- tags
|-- map.js
`-- reduce.jsLe répertoire views abrite la définition des vues MapReduce. Chaque vue a son propre répertoire et contient deux fichiers : l'un pour la fonction de subdivision (map), l'autre pour la fonction d'agrégation (reduce).
II-D. Déployer Sofa▲
Le code source est désormais sur votre disque et vous avez pu faire quelques retouches au fichier blog.json. Il est grand temps de déployer le blogue sur une instance locale de CouchDB. La commande push est simple et devrait réussir du premier coup. Toutefois, deux étapes supplémentaires sont nécessaires pour créer un compte d'administration sur votre CouchDB pour permettre vos déploiements avec CouchApp. À la fin de chapitre, vous aurez un Sofa opérationnel.
II-D-1. Envoyer Sofa à votre CouchDB▲
Chaque fois que vous modifiez le Sofa qui se trouve sur votre disque, et que vous voulez observer les changements dans votre navigateur, exécutez la commande suivante :
couchapp push . sofaCela a pour effet de déployer le code sur CouchDB. Vous devriez voir le résultat suivant :
[INFO] Pushing CouchApp in /Users/jchris/sofa to design doc:
http://127.0.0.1:5984/sofa/_design/sofa
[INFO] Visit your CouchApp here:
http://127.0.0.1:5984/sofa/_design/sofa/_list/index/recent-posts?descending=
true&limit=5Si vous rencontrez une erreur, assurez-vous que votre instance CouchDB est disponible en forgeant une requête HTTP :
curl http://127.0.0.1:5984Vous devriez recevoir :
{"couchdb":"Welcome","version":"0.10.1"}Si CouchDB n'est pas démarré, référez-vous au Chapitre 3, Premiers pas et suivez les instructions du « hello world ».
II-D-2. Tester l'application▲
Si CouchDB était disponible, alors la commande couchapp push devrait vous avoir invité à visiter l'URL de la page d'accueil. Vous y rendre devrait vous afficher quelque chose ressemblant à la Figure 14, Page d'accueil vide.
Ce n'est pas fini ! Nous avons encore quelques étapes à franchir avant d'avoir une instance opérationnelle de Sofa.
II-E. Créez votre compte d'administration▲
Sofa est une application mono-utilisateur. Vous, l'auteur, êtes l'administrateur et la seule personne qui puisse ajouter et éditer des articles. Pour vous assurer qu'autrui ne viendra pas semer le bazar, vous devez créer un compte d'administrateur dans CouchDB. C'est assez simple. Trouvez le fichier local.ini et éditez-le avec votre outil préféré (par défaut, ce fichier se trouve dans /usr/local/etc/couchdb/local.ini). Si ce n'est déjà fait, décommentez la section [admins]. Ensuite, ajoutez une ligne sous la section [admins] avec votre nom d'utilisateur préféré ainsi que votre mot de passe :
[admins]
jchris = secretpassMaintenant que votre fichier de configuration local.ini est prêt, vous devez redémarrer CouchDB pour que la modification soit prise en compte. Selon la manière dont vous avez démarré CouchDB, il y a plusieurs moyens de le redémarrer. Si vous l'avez démarré en mode console, vous pouvez presser CTRL+C puis relancer la commande antérieure ; c'est la moyen le plus simple.
Si vous n'aimez pas laisser traîner vos mots de passe dans des fichiers textes, ne vous inquiétez pas. Quand CouchDB démarre et lit le fichier, il chiffre de manière non réversible votre mot de passe, comme ceci :
[admins]
jchris = -hashed-207b1b4f8434dc604206c2c0c2aa3aae61568d6c,96406178007181395cb72cb4e8f2e66eCouchDB vous demandera désormais vos identifiants quand vous tentez de créer une base de données ou que vous voulez modifier un document - c'est tout à fait ce que vous vouliez protéger.
II-E-1. Déployer un CouchDB sécurisé▲
Maintenant que les identifiants administrateur sont définis, nous devons les fournir à couchapp push. Essayons :
couchapp push . http://jchris:secretpass@localhost:5984/sofaAssurez-vous de remplacer jchris et secretpass par vos propres identifiants, ou vous obtiendrez une erreur « permission denied ». Si tout s'est bien passé, nous avons tout configuré et vous devriez pouvoir utiliser votre blogue.
Désormais, nous sommes techniquement parés à avancer. Toutefois, vous serez bien plus heureux après avoir modifié le fichier .couchapprc comme le décrit la section suivante.
II-F. Configurer CouchAPP à l'aide de .couchapprc▲
Si vous ne voulez pas avoir à entrer l'URL complète (de surcroît avec les identifiants) de votre base de données à chaque fois que vous effectuez un envoi, vous pouvez utiliser le fichier .couchapprc pour stocker les informations de déploiement. Le contenu de ce fichier n'est pas envoyé au serveur, donc c'est un bon endroit pour conserver vos identifiants lors de l'envoi vers des serveurs sécurisés.
Le fichier .couchapprc se trouve à la racine du répertoire contenant votre application. Vous devriez regarder s'il existe dans /chemin/vers/le/répertoire/de/sofa/.couchapprc ; à défaut, créez-le. Les fichiers cachés (commençant par un point) sont souvent ignorés par les listages de répertoires. Recourez donc aux moyens que votre système d'exploitation met à votre disposition pour les afficher. Dans un terminal standard, vous pouvez normalement obtenir cette liste avec la commande ls -a, laquelle montrera tous les fichiers cachés aux côtés des fichiers normaux.
{
"env": {
"default": {
"db": "http://jchris:secretpass@localhost:5984/sofa"
},
"staging": {
"db": "http://jchris:secretpass@jchrisa.net:5984/sofa-staging"
},
"drl": {
"db": "http://jchris:secretpass@jchrisa.net/drl"
}
}
}Une fois ce fichier rempli, vous pouvez envoyer votre CouchApp à l'aide de la commande couchapp push, ce qui l'enverra vers la base de données par défaut. CouchApp est aussi capable de gérer des environnements alternatifs. Aussi, pour envoyer votre application sur une base de données de développement, vous pouvez utiliser la commande couchapp push dev. Notre expérience fait valoir l'intérêt qu'il y a à prendre le temps de définir correctement ce fichier. Un autre avantage est que votre mot de passe n'est plus affiché à l'écran.
III. Stockage des documents▲
Au cœur de CouchDB se trouve une structure de données appelée document. Pour mieux comprendre et utiliser CouchDB, vous devez penser documents. Ce chapitre vous guide à travers le cycle de vie des documents : de leur conception à leurs sauvegardes, nous passerons par leur consultation, leur agrégation et leur parcours au moyen des vues. Dans la section qui va suivre, vous verrez aussi comment CouchDB peut publier un document dans un autre format.
Les documents forment un ensemble de données autonomes. Vous avez peut-être déjà entendu parler du mot « tuple » pour indiquer quelque chose de semblable. Vos données sont souvent composées de types de données natifs tels que les entiers ou les chaînes de caractères. Les documents sont alors le premier niveau d'abstraction au-dessus de ces types de données natifs. Ils apportent une structure et regroupent de manière logique les éléments primitifs. Par exemple, la taille d'une personne peut être codée en tant qu'entier (176), mais cet entier fait souvent partie d'une structure plus vaste qui contient une étiquette ("taille": 176) et une donnée liée ({"nom":"Chris", "taille": 176}).
Le nombre d'éléments que vous stockez dans un document dépend avant tout de votre application, et aussi de la manière dont vous comptez utiliser les vues par la suite. En règle générale, un document correspond à peu de choses près à l'instance de l'objet correspondant dans votre langage de programmation. Dans le cas d'une boutique en ligne, vous aurez des objets, des ventes et des commentaires pour vos marchandises. Ce sont des candidats potentiels pour devenir des objets et, par conséquent, des documents.
Les documents se différencient subtilement des objets traditionnels, car ils appartiennent à des auteurs et permettent les opérations CRUD (pour Create, Read, Update, Delete, respectivement créer, lire, modifier, supprimer). Les logiciels de traitement de documents (comme votre logiciel de traitement de texte et votre tableur) ont conçu leur modèle de persistance des données autour du concept de document, ce qui permet aux auteurs de retrouver ce qu'ils ont écrit. De la même manière, dans une application CouchDB, vous pouvez vous réserver des marges de manœuvre vis-à-vis de la couche de présentation. Si, au lieu d'adjoindre automatiquement des estampilles temporelles (timestamps en anglais) à vos données, vous permettez à l'utilisateur de les saisir, vous obtenez par là même la possibilité de créer des brouillons qui ne seront publiés qu'une fois la date saisie atteinte. Pour cela, il suffit que votre vue utilise une endkey positionnée à now ; et cela ne vous a rien coûté !
Les fonctions de validation sont là pour vous éviter d'avoir à vous soucier de l'impact de données erronées. Dans la plupart des cas, un logiciel gérant des documents laisse le soin à l'application de modifier et de manipuler les données avant de les sauvegarder à nouveau. Tant que vous donnez à l'utilisateur le document qu'il vous a demandé de sauvegarder, il sera content.
Prenons le cas suivant : vous permettez à vos utilisateurs de rédiger un commentaire sur l'objet « livre sympathique ». Vous avez la possibilité de stocker ces commentaires dans un tableau au sein même du document de cet objet. Il est ainsi très simple de retrouver les commentaires de l'objet, mais, comme on dit, ça ne résiste pas au passage à l'échelle. En effet, un objet populaire peut avoir des dizaines, des centaines, voire des milliers de commentaires.
Aussi, plutôt que de stocker une liste de commentaires au sein même de l'objet, il serait ici préférable de les regrouper dans un recueil (en anglais, collection). CouchDB vous permet de parcourir aisément des recueils. Il est probable que vous désiriez n'en montrer qu'une dizaine ou une vingtaine à la fois et vouliez disposer de boutons « précédents » et « suivants ». En stockant individuellement les commentaires, vous pouvez les regrouper à l'aide des vues. Un groupe pourrait alors contenir tous les commentaires - ou des tranches de dix ou vingt -, le tout trié par rapport à l'objet auquel ils sont liés pour qu'il soit aisé de trouver le sous-ensemble dont vous avez besoin.
Par conséquent, une règle de base consiste à diviser en documents ce que vous gérerez individuellement dans votre application. Les objets sont unitaires, les commentaires sont unitaires, mais vous n'avez pas besoin de les redécouper. Les vues permettent de regrouper facilement vos documents de la manière qui vous intéresse.
Il est temps de concevoir notre application d'exemple pour vous montrer ce qu'il en est dans la pratique.
III-A. Format de document JSON▲
La première étape dans la conception de toute application, une fois que vous savez ce qu'est le programme et avez déterminé les interactions homme-machine, est de définir le format dans lequel vos données seront représentées et stockées. Notre blogue d'exemple est écrit en JavaScript. Un peu avant, nous avons dit que les documents représentent à peu près vos objets dans le langage que vous utilisez. Dans le cas présent, la correspondance est exacte. En effet, CouchDB a emprunté le format de données JSON à JavaScript ; ce qui nous permet d'exploiter les documents comme des objets natifs. C'est très pratique et nous évitent bien des problèmes. Si vous avez déjà travaillé avec un ORM (Object-Relational Mapping, Correspondance objet-relationnel), vous voyez quels soucis nous évoquons.
Concevons une structure JSON pour les articles du blogue. Nous savons que nous aurons besoin, pour chaque article, d'un auteur, d'un titre et d'un corps. Nous savons aussi que nous voulons utiliser l'identifiant du document pour le retrouver et ainsi faire plaisir aux moteurs de recherche. Et nous voudrions pouvoir les trier par date de rédaction.
Il devrait vous être facile de comprendrez comment JSON fonctionne. Les accolades ({}) cernent les objets, et ceux-ci sont des listes clé/valeur. Les clés sont formées par des chaînes de caractères qui sont délimitées par des guillemets doubles et droits (""). Enfin, une valeur peut être une chaîne, un entier, un objet ou un tableau ([]). Les clés sont séparées des valeurs par deux-points (:) et les couples clé/valeurs sont séparés par une virgule (,). C'est tout. Pour une description complète du format JSON, référez-vous à l'Annexe E, Introduction au JSON.
La Figure 15, La structure JSON d'un article illustre un document qui se conforme à nos exigences. Ce qui est bien, c'est que nous l'avons construit tout de suite ; c'est-à-dire que nous n'avons pas eu besoin de définir de schéma ni de préciser à quoi cela devait ressembler. Nous avons simplement créé un document contenant ce dont nous avons besoin. Et puisque les besoins liés au contenu des documents changent tout au long du processus de développement, il est aussi simple de stocker un nouveau document avec tous les champs correspondants au nouveau besoin.

Ai-je la tête de quelqu'un qui a un plan ? Savez-vous ce que je suis ? Je suis un chien qui court après les voitures. Je ne saurais qu'en faire si jamais j'en attrapais une. Vous savez, je fais juste les choses. Le malin fait des plans, les policiers font des plans, Gordon fait des plans. Vous savez, ce sont des stratèges. Les stratèges tentent de contrôler leurs petits univers. Pour ma part, je ne suis pas un stratège. Je tente de démontrer aux stratèges combien leurs tentatives de contrôler les choses sont pathétiques.
—Joker, The Dark Knight : le chevalier noir
Attardons-nous un peu sur le document. Les deux premiers attributs (_id et _rev) sont là pour CouchDB et pour identifier une instance donnée du document. Pour _id, c'est facile : si je stocke quelque chose dans CouchDB, cela crée l'identifiant _id et me l'envoie dans la réponse. Je peux ensuite utiliser cet _id dans une URL qui m'enverra le document.
L'identifiant de votre document définit l'URL à laquelle le document pourra être récupéré par la suite. Si vous avez une base de données movies, tous les documents peuvent être trouvés sous l'URL /movies, mais où précisément ?
Si vous stockez un document qui a pour _id Jabberwocky ({"_id":"Jabberwocky"}) dans votre base de données movies, il sera accessible par l'URL /movies/Jabberwocky. Donc, si vous envoyez une requête GET à /movies/Jabberwocky, vous récupérerez la structure JSON qui forme votre document ({"_id":"Jabberwocky"}).
Le numéro de version _rev indique la version d'un document. Toute modification génère un nouveau numéro de version (inclus dans le document) et met à jour le champ _rev. C'est utile, car, quand vous sauvegardez un document, vous devez fournir un numéro de version à jour pour que CouchDB sache que vous avez travaillé sur la dernière version en date du document.
Nous en avons parlé dans le Chapitre 2, Cohérence finale. Le numéro de version agit comme un garde-fou pour les opérations d'écriture dans le contexte du système MVCC de CouchDB. Un document est une ressource partagée : plusieurs clients peuvent y lire et écrire au même moment. Pour garantir que deux écritures concurrentes ne vont pas interférer, chaque client doit fournir au serveur le numéro de version sur lequel s'appuient les changements. Si ce numéro correspond à celui stocké sur le disque, alors CouchDB acceptera la modification. Dans le cas contraire, la mise à jour sera rejetée. Le client doit alors récupérer la dernière version, y intégrer les modifications et sauvegarder à nouveau.
Ce mécanisme garantit deux choses : un client peut modifier uniquement une version qu'il connaît et ne peut pas interférer avec les modifications apportées par un tiers. Cela fonctionne sans que CouchDB ait à gérer de son côté le moindre verrou. On garantit ainsi qu'aucun client n'a à attendre qu'un autre client termine sa transaction. En outre, les mises à jour sont placées dans une queue, ce qui confère deux avantages : CouchDB ne tentera pas d'écrire plus vite que votre disque ; CouchDB ne pourra pas engager deux opérations d'écritures conflictuelles au même instant.
III-B. Après _id et _rev : les données de votre document▲
Maintenant que vous comprenez le rôle des attributs _id et _rev, regardons ce le reste.
{
"_id":"Hello-Sofa",
"_rev":"2-2143609722",
"type":"post",La première chose que l'on trouve est le type de document. Notez qu'il s'agit d'un paramètre de niveau applicatif et qu'il n'a aucun impact sur CouchDB. En effet, de son point de vue, le type consiste simplement en un couple clé/valeur arbitraire. De notre point de vue, comme nous ajoutons des articles de blogue à Sofa, cela n'a guère plus de sens. En revanche, pour Sofa, le champ type détermine les fonctions de validations auxquelles le document doit être soumis. Il peut alors être certain que les documents de ce type, s'ils sont enregistrés dans Sofa, sont formatés correctement et peuvent être exploités par les vues et par l'interface utilisateur. De cette manière, l'on évite d'avoir à vérifier la présence des champs avant de les utiliser. C'est une approche purement conventionnelle, aussi pouvez-vous définir la vôtre ou déduire le type de document en fonction de sa structure (par ex., « contient un tableau avec trois cellules », ce qui est connu sous l'appellation anglaise de duck typing [NdT : le typage du canard fait référence à cette expression de James W. Riley : « si cela ressemble à un canard, nage comme un canard, cancane comme un canard, alors c'est probablement un canard »]). Nous espérons que cette explication vous convient.
"author":"jchris",
"title":"Hello Sofa",Les champs author et title sont définis quand l'article est créé. Le champ title field peut être modifié, mais le champ author est verrouillé par la fonction de validation pour des raisons de sécurité. Seul l'auteur d'un article peut l'éditer.
"tags":["example","blog post","json"],Le système de tag de Sofa se contente de les stocker dans un tableau au sein du document. Ce genre de dénormalisation [NdT : au sens des bases de données] est une bonne approche avec CouchDB.
"format":"markdown",
"body":"some markdown text",
"html":"<p>the html text</p>",Les articles de blogue sont rédigés au format HTML Markdown pour faciliter la vie de l'auteur. Le format Markdown, tel que saisi par l'utilisateur, est stocké dans le champ body. Juste avant que l'article soit sauvegardé, Sofa utilise le navigateur du client pour convertir ce champ en HTML. Il existe une fenêtre de prévisualisation du résultat de la conversion. De cette manière, vous pouvez vous assurer que le rendu correspond à ce vos vœux.
"created_at":"2009/05/25 06:10:40 +0000"
}Le champ created_at est utilisé pour trier les articles dans le flux Atom et sur la page d'accueil HTML.
III-C. La page d'édition▲
La première page que nous devons créer pour obtenir un article dans notre blogue est celle qui permet de les créer et de les éditer.
L'édition est plus complexe que le simple affichage d'un article, ce qui signifie qu'à la fin de chapitre, vous aurez vu les techniques principales auxquelles nous recourrons par la suite.
La première chose à regarder est la fonction d'affichage (en anglais, show function) utilisée pour générer une page HTML. Si ce n'est déjà fait, consultez le Chapitre 8, Fonctions d'affichage pour assimiler les détails de l'API. Nous regarderons ici le code dans le contexte de Sofa, ce qui illustre comment les briques s'assemblent parfaitement.
function(doc, req) {
// !json templates.edit
// !json blog
// !code vendor/couchapp/path.js
// !code vendor/couchapp/template.jsLa fonction d'affichage de la page d'édition de Sofa est assez simple. Dans la section précédente, nous avons montré l'importance des patrons et des bibliothèques que nous utilisons. La ligne importante est la macro !json qui charge le modèle de document edit.html qui se trouve dans le répertoire templates. Ces macros sont exécutées par CouchApp lorsque Sofa est déployé sur CouchDB. Pour plus d'informations sur les macros, référez-vous au Chapitre 13, Afficher des documents dans des formats particuliers.
// nous ne montrons que l'HTML
return template(templates.edit, {
doc : doc,
docid : toJSON((doc && doc._id) || null),
blog : blog,
assets : assetPath(),
index : listPath('index','recent-posts',{descending:true,limit:8})
});
}Le reste de la fonction est simple. Nous remplissons le modèle de document avec les données extraites du document CouchDB. Si ce document n'existe pas, nous nous assurons de positionner docid à null. Cela nous permet d'utiliser le même modèle de document pour la création et l'édition d'articles.
III-C-1. La couche HTML▲
La seule pièce manquante à l'échiquier est le code HTML nécessaire à sauvegarder un tel document.
Utilisez votre navigateur pour vous rendre sur http://127.0.0.1:5984/blog/_design/sofa/_show/edit et, avec votre éditeur de texte, ouvrez le code source du fichier templates/edit.html (ou consultez-le dans votre navigateur). Tout est paré ; la seule chose qui reste à faire est de relier le navigateur à CouchDB grâce au JavaScript. Reportez-vous à la Figure 16, Code HTML de edit.html.
Comme pour toute application web, la partie importante du code HTML est le formulaire qui permet de saisir les éditions. Ce formulaire permet de renseigner les informations basiques : le titre de l'article, le corps (au format Markdown), et les tags que l'auteur veut accoler au document.
<!-- form to create a Post -->
<form id="new-post" action="new.html" method="post">
<h1>Create a new post</h1>
<p><label>Title</label>
<input type="text" size="50" name="title"></p>
<p><label for="body">Body</label>
<textarea name="body" rows="28" cols="80">
</textarea></p>
<p><input id="preview" type="button" value="Preview"/>
<input type="submit" value="Save →"/></p>
</form>Nous commençons avec un document HTML brut contenant un formulaire HTML. Nous utilisons ensuite JavaScript pour transcrire les données saisies par l'utilisateur en un document JSON et le sauvegarder dans CouchDB. Puisque nous nous intéressons à CouchDB, nous n'allons pas détailler le JavaScript ici. C'est un mélange de code applicatif propre à Sofa, d'assistants fournis par CouchApp et de jQuery pour la partie interface. Le principe, c'est que le navigateur capture le clic sur le bouton « Save » et applique des traitements avant d'envoyer le document résultant à CouchDB.

III-D. Sauvegarder un document▲
Le code JavaScript qui gère la création et l'édition d'un article se concentre autour du formulaire HTML, comme l'indique la Figure 16, Code HTML de edit.html. Le greffon jQuery CouchApp permet quelques abstractions pour que nous puissions nous concentrer uniquement sur la manière dont le formulaire est transcrit en un document JSON lorsque l'utilisateur le soumet. $.CouchApp garantit aussi que l'utilisateur est authentifié et fournit les données de l'utilisateur à l'application. Référez-vous à la Figure 17, Délégations JavaScript pour edit.html.
$.CouchApp(function(app) {
app.loggedInNow(function(login) {La première chose que nous faisons consiste à interroger la bibliothèque CouchApp pour nous assurer que l'utilisateur est authentifié. En considérant que la réponse est positive, nous affichons la page qui correspond à un éditeur. Cela signifie que nous adjoignons un gestionnaire d'évènement au formulaire et spécifions les fonctions auxquelles sera délégué le traitement du document, à la fois quand il sera chargé et quand il sera sauvegardé [NdT : une référence vers une fonction assurant une délégation est appelée callback function en anglais].

// w00t, we're logged in (according to the cookie)
$("#header").prepend('<span id="login">'+login+'</span>');
// setup CouchApp document/form system, adding app-specific callbacks
var B = new Blog(app);Désormais, nous savons que l'utilisateur est connecté, aussi pouvons-nous afficher son nom d'utilisateur en haut de la page. La variable B est un raccourci vers un générateur de code propre à Sofa. Il contient des fonctions permettant, parmi d'autres choses, de convertir le corps de l'article du format Markdown à HTML. Nous avons placé ces fonctions dans le fichier blog.js afin d'éviter de les avoir dans le code principal.
var postForm = app.docForm("form#new-post", {
id : <%= docid %>,
fields : ["title", "body", "tags"],
template : {
type : "post",
format : "markdown",
author : login
},L'assistant app.docForm() de CouchApp est une fonction permettant de définir la correspondance entre un document CouchDB et le formulaire HTML. Examinons les trois premiers arguments qui lui sont passés par Sofa. Tout d'abord, l'argument id indique à docForm() où sauvegarder le document ; dans le cas d'un nouveau document, il est positionné à « null ». En deuxième lieu, fields reçoit un tableau contenant les éléments du formulaire qui ont une correspondance directe avec les champs JSON du document CouchDB. Enfin, l'argument template reçoit un objet JavaScript qui sera utilisé comme point de départ dans le cas d'un nouveau document. Dans le cas présent, nous nous assurons que le type du document est « post » et que le format par défaut est « markdown ». Nous définissons aussi l'auteur pour qu'il corresponde au nom d'utilisateur de la session courante.
onLoad : function(doc) {
if (doc._id) {
B.editing(doc._id);
$('h1').html('Editing <a href="../post/'+doc._id+'">'+doc._id+'</a>');
$('#preview').before('<input type="button" id="delete"
value="Delete Post"/> ');
$("#delete").click(function() {
postForm.deleteDoc({
success: function(resp) {
$("h1").text("Deleted "+resp.id);
$('form#new-post input').attr('disabled', true);
}
});
return false;
});
}
$('label[for=body]').append(' <em>with '+(doc.format||'html')+'</em>');La fonction déléguée onLoad est exécutée lorsque le document est chargé depuis CouchDB. Elle permet de mettre en forme le document avant de l'insérer dans le formulaire, ou encore d'agir sur d'autres éléments de l'interface utilisateur. Dans notre exemple, nous vérifions que le document possède déjà un identifiant. Si c'est le cas, cela signifie qu'il a déjà été sauvegardé. Aussi, nous pouvons ajouter un bouton pour le supprimer et y adjoignons une fonction déléguée pour traiter le clic. Tout cela semble exiger beaucoup de code, mais c'est, à la vérité, quelque chose de tout à fait traditionnel dans les applications Ajax. S'il y avait une critique à formuler à l'issue de cette section, ce serait de n'avoir pas déporté la logique liée à la création du bouton dans le fichier blog.js de manière à écarter les détails d'interface du code principal.
},
beforeSave : function(doc) {
doc.html = B.formatBody(doc.body, doc.format);
if (!doc.created_at) {
doc.created_at = new Date();
}
if (!doc.slug) {
doc.slug = app.slugifyString(doc.title);
doc._id = doc.slug;
}
if(doc.tags) {
doc.tags = doc.tags.split(",");
for(var idx in doc.tags) {
doc.tags[idx] = $.trim(doc.tags[idx]);
}
}
},La fonction beforeSave() délègue à docForm le traitement suivant le clic sur le bouton de soumission. Dans le cas de Sofa, cette fonction positionne l'estampille temporelle (timestamp en anglais), dérive du titre un identifiant de document acceptable (pour obtenir de belles URL) et transforme la chaîne de caractères contenant les tags en un tableau. Elle se charge aussi de la conversion du format Markdown vers le format HTML de sorte qu'une fois le document sauvegardé, l'application accède directement à la forme HTML.
success : function(resp) {
$("#saved").text("Saved _rev: "+resp.rev).fadeIn(500).fadeOut(3000);
B.editing(resp.id);
}
});La dernière fonction déléguée de Sofa se nomme success. On l'appelle dès que le document a été sauvegardé. Dans notre exemple, nous l'utilisons pour faire apparaître un message spontané à l'utilisateur qui lui indique le succès de l'opération ainsi qu'un lien pour consulter son article. De cette manière, lors de la création du document, vous pouvez immédiatement naviguer et obtenir le lien permanent vers l'article.
C'en est fait des fonctions déléguées utilisées dans docForm() !
$("#preview").click(function() {
var doc = postForm.localDoc();
var html = B.formatBody(doc.body, doc.format);
$('#show-preview').html(html);
// scroll down
$('body').scrollTo('#show-preview', {duration: 500});
});Sofa dispose d'une fonctionnalité permettant d'avoir un aperçu des articles avant de les sauvegarder. Puisque cette dernière n'affecte pas la manière dont le document est sauvegardé, le code qui guette les évènements survenant sur le bouton « preview » n'est pas inclut dans docForm().
}, function() {
app.go('<%= assets %>/account.html#'+document.location);
});
});Le dernier fragment de code ci-dessus est déclenché lorsque l'utilisateur n'est pas authentifié. Il se contente de rediriger l'utilisateur vers la page de connexion de sorte qu'il puisse s'identifier et tenter à nouveau d'éditer un article.
III-D-1. Validation▲
Désormais, vous savez comment le code précédent envoie un document JSON à CouchDB lorsque l'utilisateur clique sur « save ». Si c'est bien pratique pour créer une interface homme-machine, cela ne protège pas le moins du monde la base de données de mises à jour intempestives. C'est alors que la fonction de validation entre en scène. En effet, avec une fonction de validation adéquate, même un pirate opiniâtre ne pourra injecter de documents indésirés dans votre base. Regardons comment Sofa s'y prend. Pour plus de détails sur les fonctions de validation, référez-vous au Chapitre 7, Fonctions de validation.
function (newDoc, oldDoc, userCtx) {
// !code lib/validate.jsCette ligne importe une bibliothèque de Sofa qui rend la suite bien plus lisible. En fait, c'est une simple classe enveloppante permettant de marquer une requête comme interdite (forbidden) ou non autorisée (unauthorized). Dans ce chapitre, nous nous sommes concentrés sur la fonction de validation, aussi notez bien qu'à défaut d'utiliser validate.js de Sofa, vous devrez travailler avec la logique plus primitive que fournit la bibliothèque.
unchanged("type");
unchanged("author");
unchanged("created_at");Ces lignes font simplement ce qu'elles disent. Si les champs type, author ou created_at ont été altérés, une erreur est générée indiquant que la mise à jour est interdite. Notez que ces fonctions ne traitent pas le contenu de ces champs : elles stipulent que leur valeur ne doit pas changer d'une révision à l'autre.
if (newDoc.created_at) dateFormat("created_at");L'assistant dateFormat garantit que la date, si elle est fournie, l'est au format attendu par les vues de Sofa.
// docs with authors can only be saved by their author
// admin can author anything...
if (!isAdmin(userCtx) && newDoc.author && newDoc.author != userCtx.name) {
unauthorized("Only "+newDoc.author+" may edit this document.");
}Si celui qui sauvegarde un document est un administrateur, l'édition peut se faire. Dans le cas contraire, assurons-nous que l'auteur de l'article et celui qui l'édite présentement sont une seule et même personne. De cette manière, nous garantissons qu'un auteur peut modifier uniquement ses articles.
// authors and admins can always delete
if (newDoc._deleted) return true;Le bloc ci-dessous vérifie la validité des différents types de documents. Toutefois, comme les suppressions passent le contenu à _deleted: true, les critères ne pourront être satisfaits en cas de suppression ; c'est pourquoi les instructions sont court-circuitées par la condition ci-dessus.
if (newDoc.type == 'post') {
require("created_at", "author", "body", "html", "format", "title", "slug");
assert(newDoc.slug == newDoc._id, "Post slugs must be used as the _id.")
}
}Au final, nous obtenons la fonction de validation d'un article. Dans celle-ci, nous exigeons la présence de certains champs, ce qui nous assure qu'ils seront là quand nous construirons nos vues et notre interface graphique.
III-D-2. Publier votre article▲
Voyons comment tout cela s'emboîte ! Remplissez le formulaire avec quelques données de test et cliquez sur « save » pour obtenir la confirmation de la publication.
La figure 18, JSON encapsulé dans HTTP pour sauvegarder l'article montre la manière dont JavaScript a utilisé HTTP pour pousser (PUT) le document vers l'URL constituée du nom de la base de données et de l'identifiant du document. Elle illustre aussi la forme JSON du document envoyé dans le corps de la requête PUT. Si vous tentiez de récupérer ce document en forgeant une requête de type GET sur l'URL, vous verriez le même ensemble de données JSON avec, en plus, le champ _rev ajouté par CouchDB.
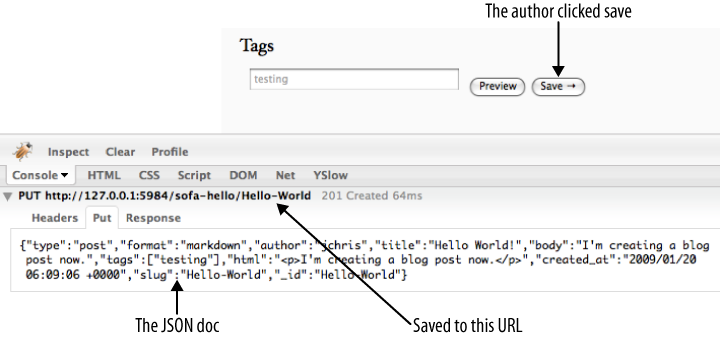
Vous pouvez aussi obtenir la version JSON du document que vous venez de sauvegarder à l'aide de Futon. Allez sur http://127.0.0.1:5984/_utils/database.html?blog/_all_docs et vous devriez voir un document avec un identifiant correspondant à celui de votre article. Cliquez dessus pour voir ce que Sofa a envoyé à CouchDB.
IV. Afficher des documents dans des formats particuliers▲
Les fonctions d'affichage de CouchDB forment un API RESTful qui trouve son inspiration dans une fonction similaire offerte par Lotus Notes. En bref, elles vous permettent de fournir le document à vos clients dans le format que vous désirez.
Une fonction d'affichage forge une réponse HTTP avec n'importe quel Content-Type et basée sur un document JSON stocké. Dans le cadre de Sofa, nous les utiliserons pour afficher les articles du blogue à partir de leur lien permanent. De cette manière, nous garantissons que ces pages pourront être indexées par les moteurs de recherche et plus facilement accessibles. La fonction d'affichage de Sofa affiche chaque article dans une page HTML qui lui est propre, avec des liens vers les feuilles de style et autres ressources, lesquelles sont des pièces jointes du design document.
La fonction d'affichage combinée à son patron (template en anglais) génèrera une page statique susceptible d'être conservée par les mécanismes d'antémémoire (en anglais, cacheable) et qui ne dépendra aucunement du contexte de la session. Elle se basera uniquement sur le document et le Content-Type demandés. La génération de code HTML dans la fonction d'affichage n'affecte pas le contenu de la base de données, ce qui en fait un atout pour la conception d'applications simples et résistantes au passage à l'échelle.
IV-A. Utiliser les fonctions d'affichage▲
Examinons le code source. Le premier élément sur lequel nous nous arrêtons est le corps de la fonction JavaScript, lequel est très simple : il appelle une fonction de patronage pour générer la page HTML. Entrons tout de même dans les détails :
function(doc, req) {
// !json templates.post
// !json blog
// !code vendor/couchapp/template.js
// !code vendor/couchapp/path.jsNous reconnaissons les macros !code et !json abordées dans le chapitre 12, Stockage des documents. Présentement, elles servent à importer un patron et quelques métadonnées décrivant le blogue (sous forme de données JSON). Elles importent aussi les liens et les fonctions de transcription.
Ensuite, nous exploitons le patron :
return template(templates.post, {
title : doc.title,
blogName : blog.title,
post : doc.html,
date : doc.created_at,
author : doc.author,L'intitulé de l'article, le corps HTML, l'auteur et la date de publication sont extraits du document conjointement avec le nom du blogue. Les trois instructions suivantes exploitent la bibliothèque path.js pour générer des liens en fonction du chemin indiqué dans la requête. Cela garantit qu'ils désigneront une ressource existante au sein de l'application.
assets : assetPath(),
editPostPath : showPath('edit', doc._id),
index : listPath('index','recent-posts',{descending:true, limit:5})
});
}Nous avons donc vu que le corps de la fonction, en lui-même, ne fait que calculer quelques valeurs (basées sur le document, la requête et quelques données spécifiques au déploiement tel que le nom de la base de données) pour les communiquer à une fonction chargée de les injecter dans le patron. Par conséquent, le cœur de l'action se trouve dans le patron HTML que nous nous proposons d'examiner.
IV-A-1. Le patron de la page de présentation d'un article▲
Le patron définit le format HTML publié, à l'exception de quelques tags qui sont substitués par du contenu dynamique. Dans le cas de Sofa, ces éléments dynamiques ressemblent à <%= replace_me %>, ce qui correspond à un délimiteur de tag classique.
Le moteur de rendu de patron utilisé par Sofa a été adapté à partir de l'article de blogue de John Resig intitulé JavaScript Micro-Templating . Il a été sélectionné car c'est le plus moteur le plus simple qui fonctionnait sans modification en étant exploité côté serveur. Recourir à un autre moteur de rendu serait un simple exercice.
Examinons la chaîne de caractères composant le patron. Rappelez-vous qu'il est inclus dans le code JavaScript par la macro CouchApp !json et que CouchApp s'occupe de le préparer en vue de son utilisation par le moteur (notamment en échappant les caractères spéciaux).
<!DOCTYPE html>
<html>
<head>
<title><%= title %> : <%= blogName %></title>C'est la première fois que nous observons un tag dans son contexte. Le titre de l'article ainsi que le nom du blogue (tel que défini dans blog.json) sont ici utilisés pour forger le tag HTML <title>.
<link rel="stylesheet" href="../../screen.css" type="text/css">Puisque les fonctions d'affichage sont appelées par le design document, elles bénéficient de son contexte, ce qui permet de pointer vers les pièces jointes avec des URI relatifs. Ici, nous faisons référence à screen.css, lequel fichier se trouve dans le répertoire _attachments à la racine du dossier contenant le code source de Sofa.
</head>
<body>
<div id="header">
<a id="edit" href="<%= editPostPath %>">Edit this post</a>
<h2><a href="<%= index %>"><%= blogName %></a></h2>De nouveau, des tags sont destinés à être remplacés par le contenu dynamique correspondant. Dans ce cas, nous pointons vers la page d'édition de l'article courant ainsi que vers la page d'accueil du blogue.
</div>
<div id="content">
<h1><%= title %></h1>
<div id="post">
<span class="date"><%= date %></span>L'intitulé de l'article est utilisé pour le tag <h1> et la date est insérée dans un tag particulier de classe date. Référez-vous à la section États dynamiques pour une explication sur la raison qui nous pousse à écrire une date statique en lieu et place d'un format plus lisible par l'utilisateur comme, par exemple, « il y a trois jours ».
<div class="body"><%= post %></div>
</div>
</div>
</body>
</html>Dans la fermeture du patron, nous transcrivons le contenu de l'article au format HTML (rappelez-vous, c'est le fruit de la traduction du format Markdown et il fut sauvegardé à partir du navigateur de l'auteur).
IV-B. États dynamiques▲
Lorsque CouchDB est abrité par un serveur mandataire assurant une fonction d'antémémoire (caching proxy en anglais), chaque fonction d'affichage ne devrait être appelée qu'une seule fois par mise à jour du document. Cela explique notamment notre préférence pour la date 2008/12/25 23:27:17 +0000 au lieu d'« il y a neuf jours ».
Cela signifie aussi que pour les éléments de présentation qui dépendent de la date actuelle, ou de l'identité de la personne qui navigue sur la page, nous aurons besoin de nous appuyer sur du code JavaScript côté client afin d'apporter les modifications de manière dynamique.
$('.date').each(function() {
$(this).text(app.prettyDate(this.innerHTML));
});Nous insérons ici ce détail de l'implémentation JavaScript du côté du navigateur non pour parler d'Ajax, mais pour démontrer l'approche la plus sensée dans le cadre de la présentation d'un document à une application client. En effet, CouchDB devrait fournir le format le plus utile pour exploiter le document, tel que le client le demande. C'est ainsi que vous épargnez des cycles processeurs et de la mémoire sur le serveur : en laissant le soin des dernières retouches de style au navigateur client. Cela s'avère tout particulièrement utile quand vous devez intégrer des données en provenance d'autres requêtes ou quand vous voulez afficher des informations synchronisées avec d'autres services web. Puisqu'il y a normalement un plus grand nombre de clients que de serveurs CouchDB, ce déport de charge vous permet de satisfaire un plus grand nombre de clients avec la même infrastructure.
V. Lister les articles▲
Les derniers chapitres visaient à insérer et extraire des données de CouchDB. Vous avez appris à modéliser vos données dans des documents et à les récupérer à l'aide de l'API HTTP. Dans ce chapitre, nous verrons comment utiliser le mécanisme de vues pour générer la page d'accueil de Sofa. Nous verrons aussi comment la fonction de listage génère la représentation HTML ou XML en fonction de la demande du client.
Puisque nous avons désormais créé un article de blogue et que nous pouvons l'afficher au format HTML, nous allons nous attaquer à la page d'accueil ; là où débarquent nos visiteurs. Cette page exhibera la liste des dix derniers articles publiés, avec leur titre et un bref résumé. La première étape consiste à écrire la fonction MapReduce qui construit l'index exploité par CouchDB lors de la requête pour y trouver les articles selon leur date de publication.
À l'occasion du chapitre 6, Trouver vos données à l'aide des vues, nous avons souligné que nous pouvions nous passer de la fonction d'agrégation (reduce en anglais) pour les requêtes basiques. Or, pour notre page d'accueil, nous voulons simplement trier les articles par date de publication ; nous n'avons donc pas besoin de cette fonction : la fonction de subdivision (map en anglais) y parvient seule.
V-A. Fonction de subdivision pour obtenir les articles récents▲
Vous êtes ainsi paré à rédiger la fonction d'agrégation qui bâtit la liste de tous les articles. L'objectif de cette vue est simple : trier ces articles par date de publication.
Ci-dessous se trouve le code source de la fonction d'affichage. Nous nous arrêterons sur les points essentiels.
function(doc) {
if (doc.type == "post") {La première chose consiste à s'assurer que le document que nous traitons est un article. En effet, nous ne voulons pas que les commentaires se retrouvent en page d'accueil. La condition doc.type == "post" est vraie uniquement pour les articles. Dans le chapitre 7, Fonctions de validation, nous avons vu que la fonction de validation nous garantit une certaine structure d'un article dans le but de nous aider à les afficher sur la page d'accueil.
var summary = (doc.html.replace(/<(.|\n)*?>/g, '').substring(0,350) + '...');Cette ligne tronque le code HTML de l'article (transcrit du format Markdown avant d'être sauvegardé) et élimine la plupart des tags et des images ; du moins, il l'épure suffisamment pour un affichage convenable sur notre page d'accueil.
La section suivante est le passage clé de la vue. Nous émettons, pour chaque document, une clé (doc.created_at) et une valeur. La clé est utilisée pour le tri et générée de sorte à pouvoir extraire rapidement les articles correspondants à une époque donnée.
emit(doc.created_at, {
html : doc.html,
summary : summary,
title : doc.title,
author : doc.author
});La valeur que nous avons émise est un objet JavaScript qui contient une partie des champs du document ainsi que le résumé que nous venons de générer. Il vaut mieux éviter d'émettre l'intégralité du document. Nous vous recommandons de garder vos vues aussi légères que possible. Aussi, n'émettez que les données que vous comptez utiliser dans votre application. Dans note cas, nous émettons le résumé (pour la page d'accueil), le code HTML (pour le flux Atom), le titre de l'article et son auteur.
}
};Vous devriez maintenant être à même de comprendre cette fonction de subdivision (map en anglais). L'appel à emit() crée une entrée dans la vue pour chaque article. Nous nommons cette vue recent-posts.
{
"_design/sofa",
"views": {
"recent-posts": {
"map": "function(doc) { if (doc.type == "post") { ... code to emit posts ... }"
}
}
"_attachments": {
...
}
}CouchApp se charge de fusionner vos fichiers locaux en un seul design document JSON, ce qui nous permet d'écrire notre vue dans le fichier views/recent-posts/map.js. Une fois que la fonction d'agrégation est intégrée au design document, notre vue est prête à l'emploi : nous pourrons y récupérer les dix derniers articles. Bien sûr, cela ressemble beaucoup à l'affiche d'un unique article. La seule différence notable est que nous obtenons désormais un tableau d'objets JSON au lieu d'un seul objet JSON.
La requête GET vers l'URI est :
/blog/_design/sofa/_view/recent-postsUne vue décrite dans le document /database/_design/designdocname dans le champ views peut être appelée à l'adresse /database/_design/designdocname/_view/viewname.
Vous pouvez passer des arguments à votre requête HTTP. Dans notre cas :
descending: true, limit: 5De cette manière, nous obtenons les cinq derniers articles.
L'URL est donc la suivante :
/blog/_design/sofa/_view/recent-posts?descending=true&limit=5V-B. Bâtir la page HTML correspondant à la vue à l'aide d'une fonction de listage▲
La fonction _list a été détaillée dans le Chapitre 5, Design Documents. Dans notre cas, nous utiliserons une fonction de listage JavaScript pour générer les formes HTML et XML à partir de la vue relatant les articles récents. Le serveur de vues JavaScript livré avec CouchDB est capable de baser sa réponse sur le résultat de la négociation HTTP et sur le contenu de l'en-tête Accept.
La fonction _list de l'API reçoit un enregistrement à la fois et envoie le résultat de la transcription au navigateur par paquet.
V-B-1. La fonction de listage de Sofa▲
Penchons-nous sur la fonction de listage de Sofa. C'est une fonction assez longue qui introduit de nouveaux concepts. Aussi, nous avancerons lentement pour nous assurer de détailler les éléments d'importance.
function(head, req) {
// !json templates.index
// !json blog
// !code vendor/couchapp/path.js
// !code vendor/couchapp/date.js
// !code vendor/couchapp/template.js
// !code lib/atom.jsLa définition de la fonction déclare attendre deux arguments, head et req. Nous n'utilisons pas head, mais uniquement req. Ce dernier qualifie la requête du client et détient ses en-têtes ainsi que la chaîne décrivant la ressource demandée (query string dans le jargon anglais). Les premières lignes de la fonction sont des macros CouchApp qui injectent du code et des données à partir d'autres fichiers du design document. Celles-ci ont été décrites dans le Chapitre 11, Gestion des design documents et permettent, en résumé, de conserver un code clair. Notre fonction de listage exploite les assistants JavaScript CouchApp pour la génération des URL (path.js), pour la gestion des dates (date.js) et pour l'exploitation des modèles de documents permettant de générer le code HTML.
var indexPath = listPath('index','recent-posts',{descending:true, limit:5});
var feedPath = listPath('index','recent-posts',{descending:true, limit:5, format:"atom"});Les deux lignes suivantes permettent de générer les URL vers la page d'accueil et vers le flux Atom correspondant. La fonction listPath se trouve définie dans path.js ; elle sait comment générer les liens vers les listes gérées par le design document qui l'appelle.
Le bloc suivant produit le code HTML destiné au blogue. Reportez-vous au Chapitre 8, Fonctions d'affichage pour le détail de l'API exploitée ici. En bref, les clients peuvent indiquer le format qu'ils préfèrent dans l'en-tête HTTP Accept ou par le paramètre format positionné dans la requête. Sur le serveur, nous indiquons quels sont les formats que nous pouvons fournir et leur associons un ordre de priorité. Ainsi, si le client accepte plusieurs formats, le premier qui a été indiqué est choisi. À noter qu'il n'est pas rare que les navigateurs déclarent accepter de nombreux formats, aussi veillez à placer le HTML au sommet des priorités. À défaut, vous pourriez envoyer du XML à un navigateur s'attendant à recevoir du HTML.
provides("html", function() {La fonction provides nécessite deux arguments : le nom du format (parmi une liste de types MIME connus) et une fonction chargée de produire le format correspondant. Notez bien que tous les appels à send et getRow doivent se faire dans la fonction provides. Bref, regardons comment le code HTML est effectivement généré :
send(template(templates.index.head, {
title : blog.title,
feedPath : feedPath,
newPostPath : showPath("edit"),
index : indexPath,
assets : assetPath()
}));La première chose que nous observons est l'appel au moteur de patronage en lui donnant le nom du blogue et quelques URL relatives. La fonction de patronage utilisée par Sofa est assez simple : elle substitue les variables prépositionnées par les valeurs qui lui sont communiquées. Ici, le patron est stocké dans la variable templates.index.head qui a été importée par la macro CouchApp du début. Le deuxième argument transmis à la fonction de patronage contient toutes les valeurs à insérer dans le patron, soit title, feedPath, newPostPath, index, et assets. Nous reviendrons plus tard sur le patron en lui-même. Pour lors, il suffit de savoir qu'il est stocké dans la variable templates.index.head et qu'il génère la partie supérieure de la page HTML, laquelle ne dépend pas du contenu de la vue comportant les articles récents.
Maintenant que l'en-tête de la page est généré, il est temps d'itérer sur les articles pour les publier un à un. Tout d'abord, déclarons nos variables et notre boucle :
var row, key;
while (row = getRow()) {
var post = row.value;
key = row.key;La variable row stocke chaque enregistrement (tuple) JSON de la vue tel qu'il est transmis à notre fonction. Quant à la variable key, nous la conservons jusqu'à la dernière itération où elle servira à produire le lien vers la page suivante.
send(template(templates.index.row, {
title : post.title,
summary : post.summary,
date : post.created_at,
link : showPath('post', row.id)
}));
}Puisque nous avons stocké le tuple et sa clé, nous pouvons appeler le moteur de patronage pour produire le code correspondant. Cette fois-ci, le patron se trouve dans templates.index.row et attend l'intitulé de l'article, l'URL de sa page, son résumé (que nous avons généré avec notre fonction de subdivision en créant la vue) et sa date de publication.
Une fois que nous avons traité l'ensemble des articles devant être inclus dans notre liste, nous pouvons la clôturer et achever la production de la page. La dernière chaîne de caractères n'a pas besoin d'être envoyée au client par la fonction send() : elle peut être retournée par notre fonction. Mis à part ce détail, la production du bas de page devrait vous être familière.
return template(templates.index.tail, {
assets : assetPath(),
older : olderPath(key)
});
});Une fois que le bas de page a été retourné, nous fermons la fonction de génération du code HTML. Si nous ne désirions pas fournir un flux Atom, nous aurions fini ici. Toutefois, nous savons pertinemment que la plupart de nos lecteurs accèderont au blogue par un agrégateur de flux, aussi cette fonctionnalité est vitale.
provides("atom", function() {La fonction de génération du flux Atom est définie de la même manière que son homologue HTML : nous recourrons à la fonction provides() avec la clé du type MIME. La structure de la fonction Atom est identique à la précédente : un en-tête, une boucle pour les articles et un bas de page.
// we load the first row to find the most recent change date
var row = getRow();La différence avec la fonction HTML est que, dans le cas de l'Atom, il est nécessaire de connaître la date de dernière modification du blogue. Cette information devrait correspondre au premier tuple de notre liste. Aussi, nous le chargeons sans l'afficher, avant que toute donnée soit envoyée au client (à l'exception des en-têtes HTTP définis quand la fonction provides capture le format), et l'utilisons pour remplir le champ last-updated.
// generate the feed header
var feedHeader = Atom.header({
updated : (row ? new Date(row.value.created_at) : new Date()),
title : blog.title,
feed_id : makeAbsolute(req, indexPath),
feed_link : makeAbsolute(req, feedPath),
});La fonction Atom.header est définie dans lib/atom.js, qui a été importée par les premières lignes de notre fonction. Cette bibliothèque exploite l'extension JavaScript E4X pour générer le flux XML.
// send the header to the client
send(feedHeader);Puisque les en-têtes du flux ont été générés, nous les envoyons au client à l'aide de la fonction send(). C'en est alors fini des en-têtes et nous pouvons produire chaque élément du flux à partir d'un tuple de la vue. Nous utilisons ici une boucle légèrement différente de celle de tantôt puisque nous avons déjà chargé le premier enregistrement pour générer les en-têtes.
// loop over all rows
if (row) {
do {La boucle JavaScript do/while ressemble à la boucle while utilisée par la fonction HTML, à la différence notable qu'elle sera exécutée au moins une fois. Ceci car le test de la condition d'itération se fait après avoir exécuté le corps de la boucle. Nous pouvons ainsi générer l'entrée correspondant à l'article que nous avons chargé en mémoire au début avant d'appeler la fonction getRow() pour charger le suivant.
// generate the entry for this row
var feedEntry = Atom.entry({
entry_id : makeAbsolute(req, '/' +
encodeURIComponent(req.info.db_name) +
'/' + encodeURIComponent(row.id)),
title : row.value.title,
content : row.value.html,
updated : new Date(row.value.created_at),
author : row.value.author,
alternate : makeAbsolute(req, showPath('post', row.id))
});
// send the entry to client
send(feedEntry);La génération des éléments exploite aussi la bibliothèque Atom définie dans atom.js. Il y a une différence notable entre les éléments d'une liste HTML et ceux d'un flux Atom. Dans le premier cas, nous n'affichons que le résumé de l'article tandis que, dans le second, nous produisons l'ensemble de l'article. En substituant, pour content, row.value.html à row.value.summary, vous pourriez publier uniquement le résumé, ce qui aurait pour effet de contraindre vos visiteurs à cliquer sur l'article pour le consulter.
} while (row = getRow());
}Comme nous l'avons expliqué plus tôt, ce type de boucle repousse l'évaluation de la condition d'itération à la fin de la boucle, d'où il suit que le prochain tuple n'est chargé qu'à la fin de la boucle.
// close the loop after all rows are rendered
return "</feed>";
});
};Une fois que tous les enregistrements ont été parcourus, nous clôturons le flux en fermant la balise XML et en l'envoyant au client.
V-B-2. Résultat▲
La Figure 20, La page d'accueil ainsi générée illustre le résultat.
Ceci est notre liste des articles du blogue. Ce n'est pas si difficile, n'est-ce pas ? Nous avons désormais la page d'accueil, savons récupérer un seul document tout comme toute une vue et nous avons comment transmettre des arguments aux vues.
VI. Remerciements▲
Un livre O'Reilly traitant de CouchDB écrit par J. Chris Anderson, Jan Lehnardt et Noah Slater ; traduit de l'anglais par Jil Larner. Merci aussi à s0h3ck pour la gabarisation et à XXX pour la relecture orthographique.